Frame Sampling for Data Augmentation
Data augmentation is a crucial technique in machine learning for increasing the effective size of training datasets and improving model robustness. In the context of the Ariel Data Challenge 2025, where we’re working with time-series spectroscopic data, frame sampling presents an interesting approach to create multiple training examples from each planet’s observation sequence.
Checkout the frame sampling notebook on GitHub.
1. The Motivation
Each planet in our dataset consists of a sequence of spectroscopic frames captured during transit observations. Rather than using the entire sequence as a single training example, we can strategically sample subsets of frames to create multiple training instances from each planet. This approach offers several advantages:
- Increased training data: More examples for the machine learning model to learn from
- Smaller input frames: Using a subset of each time-series will reduce the size of each input image
- Faster training time: Smaller inputs will allow faster training times & more training experiments
- Uncertainty estimation: Having multiple feature sets for the same label enables bootstrapping and ensemble methods
2. Sampling Strategy
2.1. Random frame selection
The sampling approach randomly partitions the observation time indices into n groups, then sorts by increasing time index within each group to preserve temporal order. For our test case with planet 4169614766, we generated 12 different samples from the original sequence of 5,426 frames.
2.2. Size normalization
To ensure consistent input dimensions for machine learning models, all samples are normalized to the same number of frames. The algorithm:
- Randomly divides frames into the desired number of sample groups
- Orders by time index within each sample group
- Identifies the smallest sample size (452 frames in our case)
- Truncates all samples to this minimum size
- Results in a final sample array of shape (12, 452, 283) (for 12 samples)
This process only resulted in 2 frames being lost - quite efficient for a 5,426 frame dataset!
3. Visualization Results
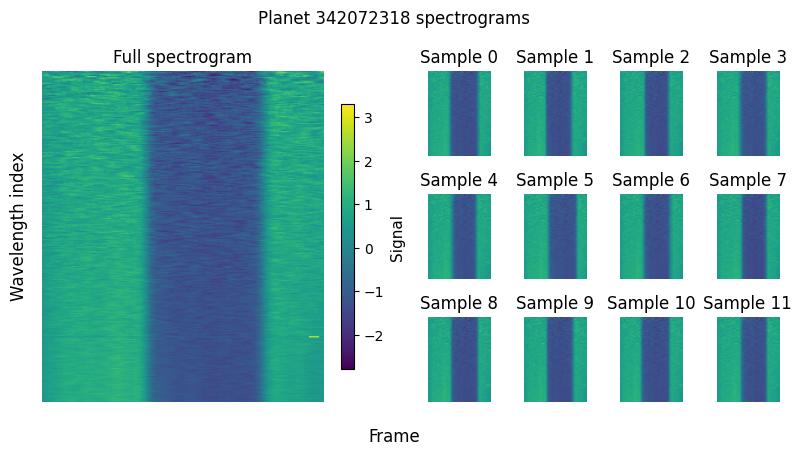
The visualization shows the power of this sampling approach. On the left, we see the full spectrogram for planet 342072318 with all its temporal and spectral information. On the right, we see 12 different samples, each representing a subset of randomly selected frames from the original sequence.
Each sample maintains the essential spectral characteristics while introducing diversity and expanding the number of different training examples. This diversity is exactly what we want for training robust machine learning models - the algorithm learns to extract planetary atmospheric signatures regardless of which specific frames it observes.
4. Implementation Insights
The sampling process is remarkably straightforward but effective:
- Efficiency: Minimal data loss (only 2 frames out of 5,426 for 12 samples)
- Flexibility: The number of samples and minimum frame count can be easily adjusted
- Randomization: Each sample represents a different ‘version’ of the observed spectrum for the same planet
The ability to multiply our training data while maintaining physical meaning is a powerful tool for developing robust machine learning models. With this last trick implemented, I think we are finally ready to start training models!