Performance Optimization: Making the Pipeline Kaggle-Ready
The signal correction pipeline works beautifully, but there’s one small problem: it takes forever to run. With 1100 planets to process and a 9-hour runtime limit on Kaggle submission notebooks, we needed some serious performance optimization. Time to make this thing fast.
Checkout the full benchmarking notebook on GitHub.
1. The performance challenge
Initial testing revealed a harsh reality: just signal correcting the full dataset would take longer than the competition’s 9-hour runtime limit on Kaggle notebooks. We needed two key optimizations:
- Data parallelization - Use multiple CPU cores to process planets simultaneously
- FGS downsampling - Reduce the FGS1 data volume by selecting only frames which match the AIRS-CH0 capture cadence
Both changes target the biggest bottlenecks: computation time and data volume.
2. FGS1 downsampling
The FGS1 guidance camera captures 135,000 frames per planet, while AIRS-CH0 only captures 11,250. We reduce the amount of data significantly by downsampling to match the AIRS-CH0 timing.
The downsampling strategy takes every 24th frame pair from the FGS1 data, reducing the number of frames to ~15% of the raw count, while preserving the correlated double sampling structure.
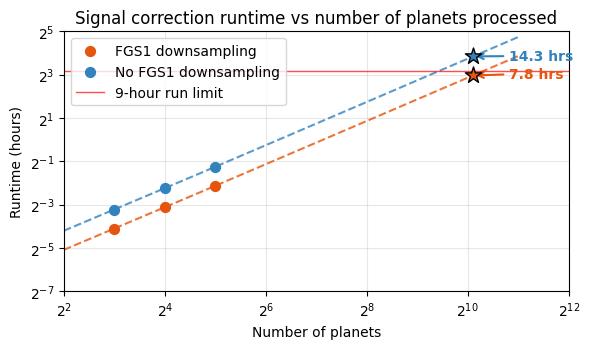
Results: Downsampling cuts predicted runtime almost in half. For 1100 planets:
- Without downsampling: 14.3 hours (major fail)
- With downsampling: ~7.8 hours (under the time limit, but could be better)
3. Multiprocessing: divide and conquer
With downsampling we make the time cutoff, but it would be great to have more time left over after signal correction. Time to parallelize across multiple CPU cores. The pipeline now uses multiprocessing to handle multiple planets simultaneously, with separate worker processes for signal correction and a dedicated process for saving results.
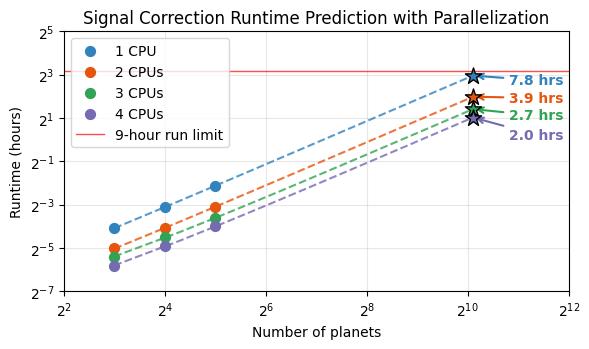
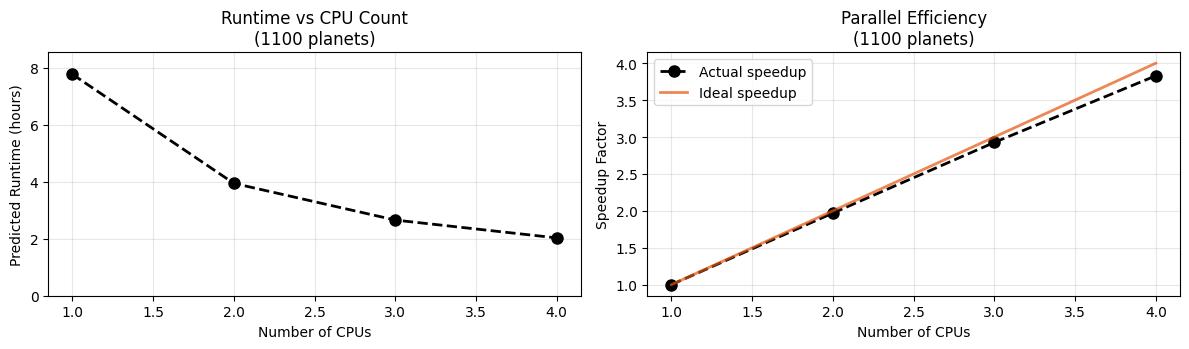
Results: The speedup is significant but shows diminishing returns:
- 1 CPU: 7.3 hours (downsampled baseline)
- 2 CPUs: 3.9 hours (2.0x speedup)
- 3 CPUs: 2.7 hours (2.9x speedup)
- 4 CPUs: 2.0 hours (3.8x speedup)
4. Memory usage
Parallelization comes with a memory cost. More worker processes mean more data in memory. Let’s also make sure we can run all 4 avalible cores in a free tier Kaggle notebook simultaneously and not run out of memory:
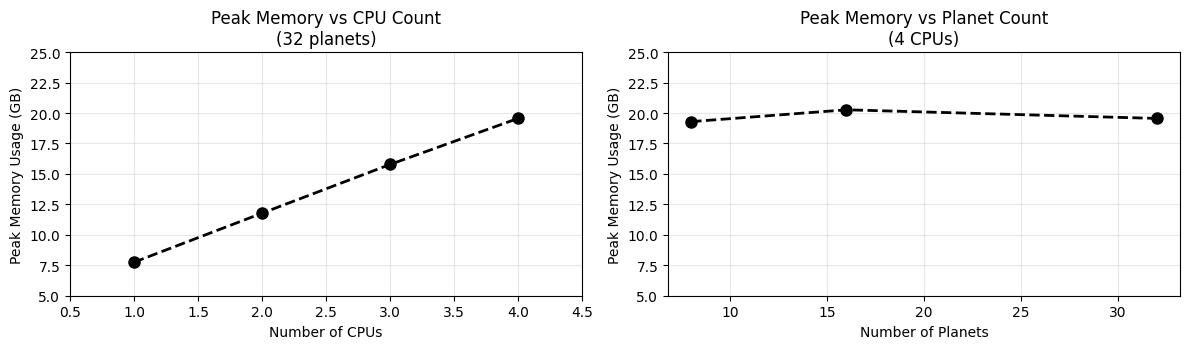
Memory scaling for 32 planets:
- 1 CPU: 7.8 GB
- 2 CPUs: 11.8 GB
- 3 CPUs: 15.8 GB
- 4 CPUs: 19.6 GB
The memory usage grows roughly linearly with CPU count at ~4.4 GB per additional core, up to ~20 GB with 4 cores. Also, the memory footprint is independent of how many planets we process. This makes sense, since each worker processes one planet at a time, the total memory should only depend on the number of workers. Conclusion: were safe - the data will fit in a Kaggle notebook’s memory, even with all available cores pegged.
5. The sweet spot: 3-4 CPUs
The performance analysis reveals the optimal configuration:
- 3 CPUs: 2.6 hours, ~13 GB memory (safe choice)
- 4 CPUs: 2.0 hours, ~20 GB memory (maximum performance)
Both configurations beat the 9-hour limit without exceeding the memory available in a Kaggle notebook. The 4-CPU setup gives the best performance with a comfortable 7-hour margin for the rest of the inference pipeline. But, I think three cores is going to be the sweet spot. These tests were run on a machine with more than 4 cores, while the Kaggle notebook environment has ONLY 4. Trying to run signal correction workers on all 4 cores will leave none for the output worker - to say nothing of the host OS. Either way, we can comfortably preprocess the data within the time and memory limits.
6. Implementation details
The optimized pipeline uses:
- Process pools for planet-level parallelization
- Shared queues for inter-process communication
- Smart downsampling that preserves CDS structure
All of this is now packaged and available via pip install ariel-data-preprocessing, making it easy to deploy on Kaggle or any other platform.
7. Result summary
What started as a 14+ hour processing job is now down to about 2 hours with 4 CPUs - a 7x speedup at the cost of 2.5x increase in total memory footprint. I’ll take that deal!
Next up, let’s try and reduce the size of the data and the noise further by extracting just the signal from each frame.